
CI/CD security community organizing sounds like a niche security phrase until a build breaks, a token leaks, or a dependency maintainer asks for help and nobody knows who should respond.
Teams think the problem is pipeline hardening. The real problem is coordination under uncertainty. A secure build system still fails operationally when the right people are not reachable, when nobody owns the handoff, or when an alert lands in a channel where everyone assumes someone else is handling it.
That matters more in 2026 because local networks are increasingly technical. Community projects run websites, payment flows, volunteer tools, neighborhood data, grant reporting systems, and shared infrastructure. Many are built by freelancers, part-time maintainers, civic technologists, and small operators. The software supply chain is not abstract. It is the calendar, the food pantry intake form, the local marketplace, the mutual aid routing sheet, and the community app.
The practical question is not: how do we teach everyone DevSecOps? The practical question is: how do we build a community operating model where CI/CD security signals turn into reliable asks, offers, routing, ownership, and follow-up?
This guest contribution comes from the team at vu1nz.com, and the goal here is simple: translate CI/CD security into a coordination pattern that local organizers and network operators can actually run.
Table of contents
- CI/CD security community organizing is an operating model
- Map the pipeline like a neighborhood route
- Build trust before the incident
- Turn alerts into community coordination
- Choose lightweight security controls that organizers can sustain
- Define escalation paths for supply chain issues
- Run tabletop drills that create useful memory
- Measure CI/CD security community organizing, not just tooling
- Common failure modes in local CI/CD security work
- Make the network durable with d0rz.com
CI/CD security community organizing is an operating model
Not another security channel
The mistake teams make is treating CI/CD security community organizing as a chat room with a better name. They create a security channel, invite the technical people, post scanner output, and call it collaboration.
That works until the first ambiguous incident. A dependency gets flagged. A GitHub Action starts behaving differently. A contractor pushed a workflow change before going offline. The nonprofit director wants to know if donor data is affected. The maintainer says the build is blocked. The volunteer who set up the original deployment moved to another city.
A channel is not an operating model. It does not define who validates the signal, who can pause deployment, who contacts the maintainer, who informs the community, or who confirms the issue is actually closed.
Practical rule: If a security signal does not have a named next owner within fifteen minutes, it is not routed. It is just visible.
Why local networks belong in the workflow
Local networks already understand the hard part: trust routing. Who knows the church basement schedule? Who can reach the translator group? Who has keys to the space? Who can verify whether a new volunteer is legitimate? The same operating instincts apply to CI/CD security.
The pipeline is not only code. It is a chain of people, credentials, tools, repositories, vendors, maintainers, and release decisions. Some are formal. Many are informal. In community projects, the informal layer is often where the real knowledge lives.
That changes the conversation. Instead of asking local organizers to become security engineers, we ask them to help maintain the social infrastructure around software risk: who is trusted, who can verify, who can escalate, and who must be informed.
The unit of work is the handoff
A useful way to think about it is this: the pipeline fails at handoffs. Code moves from contributor to repository. Repository moves to CI. CI moves to artifact. Artifact moves to deployment. Deployment moves to users. Alerts move to humans. Humans move decisions to other humans.
CI/CD security community organizing is the discipline of making those handoffs explicit enough that a small, distributed network can defend them.
The output is not a giant policy document. The output is a set of routing rules, contact paths, escalation agreements, and follow-up habits that survive a messy week.
Map the pipeline like a neighborhood route
Find the handoffs
Start by mapping the route, not the tools. Draw the path from idea to production and mark every place where control changes hands.
For a typical community project, the path may look like this:
- A volunteer or freelancer opens a pull request.
- A maintainer reviews the change.
- CI runs tests, dependency checks, and build steps.
- Secrets are accessed during build or deployment.
- An artifact is published or a container is pushed.
- Deployment updates a public service.
- Users, organizers, or partners notice the effect.
Each step has a security question attached. Who can change it? Who can approve it? Who can observe it? Who can reverse it?
The practical question is not whether your pipeline is perfect. It is whether your network knows where the risky turns are.
Name owners, not spectators
Many local technical projects have a hidden ownership problem. Everyone is nearby, nobody is accountable. A repository has five admins. A hosting account uses a shared email. A deployment workflow was written by someone who is no longer active. The community assumes the technical team has it. The technical team assumes the organizer will decide whether to notify users.
Name owners for each handoff:
- Repo owner: approves access and branch protections.
- CI owner: maintains workflow files and runner configuration.
- Secrets owner: rotates tokens and manages environment variables.
- Release owner: decides whether to pause, ship, or roll back.
- Community owner: handles user-facing communication.
- Follow-up owner: records decisions and confirms remediation.
This does not require bureaucracy. It requires a current list and a default backup.
Track weak signals
Weak signals are the small events that rarely trigger a full incident but often indicate drift:
- A new GitHub Action appears in a workflow.
- A dependency update changes install behavior.
- A contributor requests elevated repository access.
- A build starts taking much longer than usual.
- A token expires and someone asks for a quick workaround.
- A maintainer says they are overloaded and need help merging.
Most communities ignore weak signals because they do not look urgent. In practice, weak signals are where community organizing has the most leverage. They are early enough to route calmly.
Practical rule: Track weak signals in the same place you track community asks. Security work becomes easier when it is routed before it becomes an emergency.
Build trust before the incident
Maintain a working directory
You cannot coordinate a CI/CD security issue if you do not know who is allowed to act. A working directory is a living map of people, roles, and contact paths.
Keep it simple:
| Role | Primary person | Backup | Can approve | Contact path |
|---|---|---|---|---|
| Repository admin | Named maintainer | Named backup | Access changes | Direct message plus email |
| CI workflow owner | Build maintainer | Dev volunteer | Workflow edits | Project channel |
| Secrets owner | Ops lead | Treasurer or admin | Token rotation | Phone for urgent issues |
| Community comms | Organizer | Program lead | User notices | Messaging group |
| Vendor contact | Contract owner | Finance lead | Support ticket | Vendor portal |
The directory should answer two questions quickly: who can do the work, and who is trusted to say yes.
Separate public asks from private details
Community networks thrive on visibility, but security work needs boundaries. Do not post leaked tokens, suspicious payloads, private logs, user data, or exploit details in public community channels. Do post the coordination need.
Use a pattern like:
Ask: Need CI workflow owner to review an unexpected dependency install step.
Context: Possible supply chain risk in the website deployment pipeline.
Sensitivity: Do not share logs publicly. Details available to repo admin and CI owner.
Deadline: Initial review needed today before next deploy.
Owner: Maya is coordinating.
That gives the network enough information to help without widening exposure.
Use small commitments
The best trust systems are built through small reliable actions before a crisis. Ask people to take bounded roles:
- Review one workflow file this month.
- Confirm who owns one token.
- Attend a thirty-minute release drill.
- Be backup contact for one project.
- Document one rollback path.
Small commitments reveal who follows through. That is more useful than a long list of people who once expressed interest.
Turn alerts into community coordination
Triage the ask
An alert is not automatically an incident. It is a signal that needs triage. The first operator should convert the alert into a clear ask.
A practical triage template:
Signal: Dependency scanner flagged package X in repository Y.
What changed: New version introduced in pull request 184.
Potential impact: Build-time code execution possible during install.
Immediate decision: Pause deploy or continue after review.
Needed people: Repo owner, CI owner, release owner.
Deadline: Before 3 pm release window.
Public message needed: Not yet.
This moves the work from panic to routing. It also prevents the common failure where ten people discuss severity while nobody checks the actual pipeline.
Route to the right circle
Not every issue belongs in the same room. Use circles:
- Public circle: general awareness, low sensitivity, help requests.
- Operator circle: maintainers, CI owners, release owners, organizers.
- Restricted circle: secrets, exploit details, user data, legal or vendor contacts.
The mistake teams make is choosing between total secrecy and total broadcast. Local networks need graduated visibility. People should know enough to help, not enough to accidentally spread sensitive material.
Practical rule: Route by decision rights. If someone cannot help decide, fix, communicate, or validate, they probably do not need sensitive details.
Close the loop
What breaks in practice is closure. The alert gets fixed, the thread goes quiet, and nobody records what happened. Two months later the same pattern appears in another project.
Close every meaningful signal with four lines:
Outcome: Workflow file updated and untrusted action removed.
User impact: None observed.
Follow-up: Pin third-party actions by commit SHA across all projects.
Owner and date: Jules by Friday.
Closure is not paperwork. It is how the network learns.
Choose lightweight security controls that organizers can sustain
What works
The control stack for a local network should be boring, visible, and maintainable. Prefer controls that reduce risky decisions without requiring constant expert attention.
Good defaults include:
- Branch protection on production branches.
- Required review for workflow file changes.
- Least-privilege tokens for CI jobs.
- Short-lived credentials where supported.
- Pinned third-party actions or verified publishers.
- Dependency review on pull requests.
- Separate build and deploy permissions.
- Environment approvals for production deploys.
- Basic artifact signing where the team can operate it.
The point is not to install every security product. The point is to make unsafe paths harder than safe paths.
What fails
Controls fail when they ignore how the community actually works.
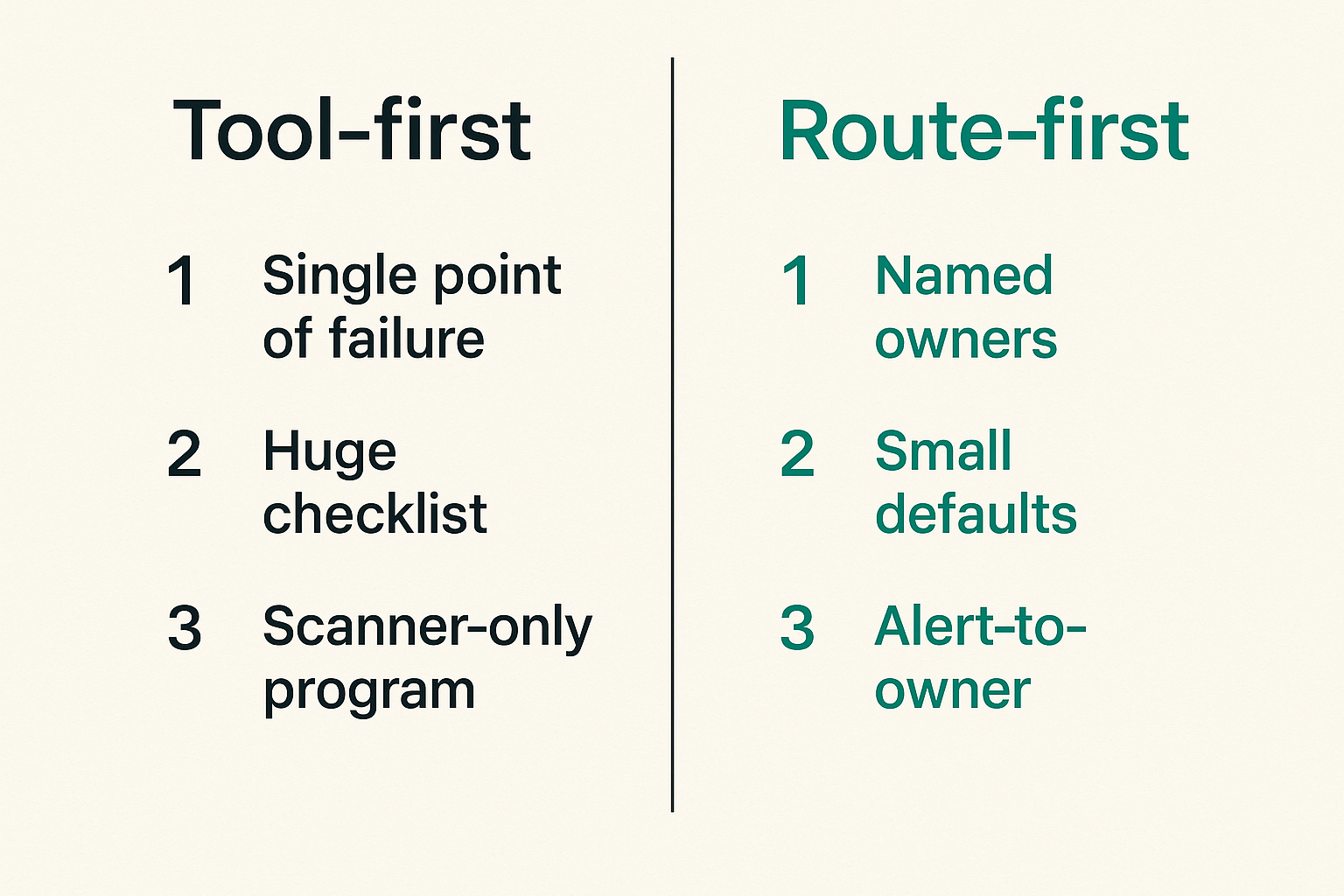
| Approach | Looks good because | Fails because | Better pattern |
|---|---|---|---|
| One admin owns everything | Fast decisions | Single point of failure | Named primary and backup owners |
| Huge security checklist | Comprehensive | Nobody maintains it | Small required defaults per project |
| Public incident thread | Transparent | Sensitive details leak | Public ask plus restricted details |
| Scanner-only program | Automated | Alerts lack ownership | Alert-to-owner routing rule |
| Volunteer heroics | Gets things done | Burns out key people | Rotating response roles |
What fails is not usually intent. It is operational load. A control that depends on one tired maintainer remembering every edge case is not a control. It is a wish.
A practical control stack
For most community-run software, start with a minimum baseline:
- Inventory active repositories and deployment targets.
- Turn on branch protections for production branches.
- Require review for CI workflow changes.
- Remove long-lived shared credentials from workflows.
- Limit CI tokens to the permissions each job needs.
- Add dependency review to pull requests.
- Document rollback for each public service.
- Create a restricted operator circle for sensitive details.
- Run one drill per quarter.
- Review owners monthly.
This is not glamorous. It works because it matches the rhythm of small teams and local networks.
Define escalation paths for supply chain issues
Severity should include blast radius
Security severity is often discussed as if it lives only inside the vulnerability. For community operators, severity also depends on blast radius.
Ask:
- Does this affect a public service or an internal tool?
- Does the pipeline touch user data, payments, location, or health information?
- Can the compromised step deploy to production?
- Are secrets exposed to the job?
- How many partner organizations depend on this system?
- Is there a real-world event or deadline that changes risk?
A medium technical issue can be a high operational issue if it affects a service people rely on tonight.
Pre-approve response roles
During an incident, people should not negotiate authority from scratch. Pre-approve who can make time-sensitive decisions.
Recommended roles:
- Incident coordinator: keeps the timeline and routes decisions.
- Technical validator: confirms the signal and scope.
- Pipeline operator: pauses jobs, rotates credentials, rolls back.
- Community communicator: prepares external messaging if needed.
- Partner contact: handles vendors, funders, venues, or civic partners.
- Recorder: captures decisions, timestamps, and follow-up tasks.
One person can hold more than one role in a small group. The important part is that the roles exist before pressure arrives.
Keep vendors and maintainers in view
CI/CD security is full of external dependencies. Hosting platforms, package registries, open-source maintainers, contractors, SaaS vendors, and payment providers can all become part of the response path.
Do not wait until an issue to find support contacts. Keep a short vendor and maintainer map:
Service: Hosting provider
Used by: Community directory and events site
Account owner: Ops lead
Support path: Paid support ticket
Emergency notes: Can disable deploy token and roll back to previous release
For open-source dependencies, the contact path may be an issue tracker rather than a named person. That is fine. The point is to know the route.
Run tabletop drills that create useful memory
Drill the uncomfortable scenarios
Tabletops should not be theatrical. They should expose missing routes. Pick scenarios that match how local projects actually fail:
- A volunteer accidentally commits a secret.
- A third-party GitHub Action is compromised.
- A maintainer account is taken over.
- A dependency begins running unexpected install scripts.
- A deployment breaks the public intake form before a major event.
- A vendor account owner is unavailable during a security notice.
Run the drill for forty-five minutes. Do not solve everything. Watch where the group gets stuck.
Capture decisions, not theater
A useful drill produces decisions:
Decision: Production deploys can be paused by either release owner or backup.
Decision: Secrets owner will rotate tokens within four hours of suspected exposure.
Decision: Public updates require approval from community comms and incident coordinator.
Decision: Workflow changes require review from CI owner after this date.
If the only output is a meeting summary, the drill did not improve the system.
Publish the working notes
Publish the non-sensitive notes where the network can find them. Include:
- Scenario tested.
- Who attended.
- Where routing failed.
- Decisions made.
- Follow-up tasks.
- Next review date.
This is how a local network builds institutional memory without becoming a formal bureaucracy.
Measure CI/CD security community organizing, not just tooling
Useful metrics for operators
You do not need a dashboard with twenty charts. You need a few measures that tell you whether coordination is improving.
Useful metrics include:
- Time from signal to named owner.
- Time from owner to initial decision.
- Percentage of active projects with current owners.
- Percentage of production workflows requiring review.
- Number of unresolved weak signals older than two weeks.
- Number of drills completed this quarter.
- Follow-up completion rate after incidents or drills.
These metrics are not about looking mature. They show whether asks are turning into action.
Bad metrics that create noise
Bad metrics reward activity without improving safety:
- Total alerts generated.
- Total messages posted in security channels.
- Total tools installed.
- Total pages in the policy document.
- Total people invited to a response group.
More alerts are not the same as better security. More people in a channel can make routing worse. More policy can hide the fact that nobody owns the token.
The mistake teams make is measuring visibility instead of movement.
Review cadence
Use a rhythm that matches community operations:
- Weekly: check urgent unresolved security asks.
- Monthly: review owners, backups, and weak signals.
- Quarterly: run a tabletop drill.
- After every incident: record outcome and follow-up.
- Before major events: confirm deployment, rollback, and contact paths.
This cadence keeps security close to actual work. It also reduces the need for heroic catch-up after something breaks.
Common failure modes in local CI/CD security work
Tool-first organizing
Tool-first organizing starts with the platform: buy the scanner, configure the bot, generate the report. The first month feels productive. Then alerts pile up, maintainers mute notifications, and organizers stop trusting the feed.
The fix is to start with routing. Before adding another tool, answer:
- Who receives the signal?
- Who validates it?
- Who can change the pipeline?
- Who decides user communication?
- Where is closure recorded?
A tool that fits into this path can help. A tool that bypasses it creates noise.
Hero routing
Every network has a person who knows everything. They know where the credentials are, which vendor to call, which workflow is fragile, and which maintainer is likely to respond. They are useful. They are also a risk.
Hero routing feels efficient until the hero is unavailable. Then the community discovers that knowledge was never infrastructure.
Convert hero knowledge into shared routes:
- Ask the hero to name backups.
- Record the top five recurring security tasks.
- Pair a second person on token rotation.
- Move private notes into a restricted shared space.
- Rotate incident coordinator duties.
Do not punish the hero. Extract the pattern and make it survivable.
No memory after the fix
The most expensive failure is forgetting. A secret leaks, gets rotated, and everyone moves on. A workflow is abused, gets patched, and nobody checks sister projects. A vendor notice arrives, gets handled by one person, and the route disappears again.
No memory means every incident starts from zero.
The practical fix is a lightweight record:
Date: 2026-06-04
Project: Local services portal
Signal: Secret exposed in CI log
Decision: Rotate token, disable log access, audit recent deploys
Related projects to check: Events site, partner intake form
Follow-up owner: Sam
Review date: 2026-06-18
This is enough to create continuity.
Make the network durable with d0rz.com
Where d0rz.com fits
CI/CD security community organizing is a routing problem before it is a tooling problem. That is where local coordination infrastructure matters.
A community network needs a place to track trusted people, active asks, available offers, follow-up commitments, and the routes between them. Security work should not live in a forgotten spreadsheet or a noisy general chat. It should connect to the same operating layer the community already uses for coordination.
d0rz.com fits when you are trying to make local participation more reliable: who can help, who is trusted for a specific kind of work, what needs follow-up, and which relationships can move an issue forward. For CI/CD security, that means turning vague concern into routed action without forcing every organizer to become a pipeline specialist.
The product is not a replacement for source control, CI platforms, scanners, or incident tools. It is the connective tissue around them.
Final checklist
If you are starting this week, keep it small:
- Pick one active community software project.
- Map its build and deploy handoffs.
- Name owners and backups for repository, CI, secrets, release, and community communication.
- Create one restricted operator circle for sensitive details.
- Add a simple alert-to-ask template.
- Require review for workflow changes.
- Record weak signals for one month.
- Run one tabletop drill.
- Close every issue with outcome, impact, follow-up, owner, and date.
- Review the route after the next real incident.
The practical question is not whether you can design the perfect program. It is whether the next signal will reach the right person fast enough to matter.
That is the real work of CI/CD security community organizing.
Try d0rz.com
Build practical local networks where asks, offers, trust, routing, and follow-up become coordination infrastructure. If you are making CI/CD security community organizing part of your local operating model, Try d0rz.com.